Abstract
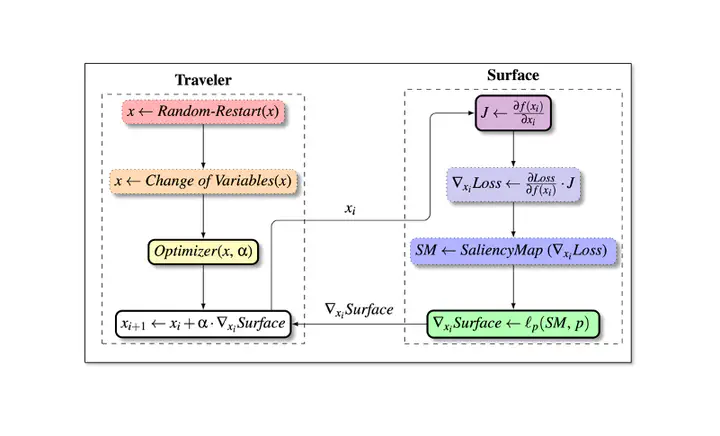
Adversarial examples, inputs designed to induce worst-case behavior in machine learning models, have been extensively studied over the past decade. Yet, our understanding of this phenomenon stems from a rather fragmented pool of knowledge; at present, there are a handful of attacks, each with disparate assumptions in threat models and incomparable definitions of optimality. In this paper, we propose a systematic approach to characterize worst-case (i.e., optimal) adversaries. We first introduce an extensible decomposition of attacks in adversarial machine learning by atomizing attack components into surfaces and travelers. With our decomposition, we enumerate over components to create 576 attacks (568 of which were previously unexplored). Next, we propose the Pareto Ensemble Attack (PEA): a theoretical attack that upper-bounds attack performance. With our new attacks, we measure performance relative to the PEA on: both robust and non-robust models, seven datasets, and three extended ℓp-based threat models incorporating compute costs, formalizing the Space of Adversarial Strategies. From our evaluation we find that attack performance to be highly contextual: the domain, model robustness, and threat model can have a profound influence on attack efficacy. Our investigation suggests that future studies measuring the security of machine learning should: (1) be contextualized to the domain & threat models, and (2) go beyond the handful of known attacks used today.